

Big Data, Bigger Opportunities: Uncover Apache Spark’s Processing Magic!
In today’s digital era, data is the fuel that drives innovation and business success. Companies of all sizes are amassing extensive amounts of facts from numerous resources, which includes social media, sensors, consumer interactions, and greater. The undertaking lies now not best in collecting this statistics but additionally in processing and deriving valuable insights from it. That is in which Apache Spark, an open-supply allotted computing device, comes into play, revolutionizing the manner large statistics is dealt with and analyzed.
Table of Contents
- What is Apache Spark?
- Key Features of Apache Spark:
- Spark Architecture:
- Apache Spark Components:
- Use Cases of Apache Spark:
- Conclusion:
What is Apache Spark?
Apache Spark is a fast and general-purpose cluster computing system designed for large-scale data processing(Data Engineering). It was initially developed in 2009 at the University of California, Berkeley’s AMPLab and later open-sourced in 2010.
In view that then, it has grown into one of the most broadly followed large facts processing frameworks, attracting a vibrant and energetic community.
At its center, Spark is built across the concept of Resilient allotted Datasets (RDDs).
RDDs are fault-tolerant, immutable collections of records that can be processed in parallel throughout a cluster of machines. This fault-tolerance property ensures that Spark can recover from failures and maintain data consistency throughout the processing pipeline.
Key Features of Apache Spark:
- Speed: Spark’s in-memory computing capability allows it to cache data in memory, dramatically accelerating data processing compared to traditional disk-based systems like Hadoop MapReduce.
- Ease of Use: Spark provides APIs in Java, Scala, Python, and R, making it accessible to developers with different language preferences. Its simple and expressive APIs allow users to focus more on solving problems and less on dealing with the complexities of distributed systems.
- Versatility: Spark supports various data processing tasks, including batch processing, real-time stream processing, machine learning, and graph processing, all within a single framework.
- Scalability: Spark is horizontally scalable, meaning it can efficiently distribute the workload across a cluster of machines, making it well-suited for handling large datasets.
Spark Architecture:
Apache Spark follows a flexible and extensible architecture that supports different deployment and execution modes, catering to various use cases and requirements. Here are the main architecture types of Apache Spark:
Standalone Mode:
Standalone mode, also known as Spark Standalone or Spark Cluster Manager, is the simplest deployment architecture for Spark. In this mode, Spark comes with its built-in cluster manager, which allows you to set up a Spark cluster on a group of interconnected machines. It does not rely on external cluster management frameworks like Hadoop YARN or Apache Mesos.
Hadoop YARN Mode:
Apache Hadoop YARN (Yet Another Resource Negotiator) is a resource management layer in the Hadoop ecosystem. Spark can be integrated with YARN, allowing it to run on Hadoop clusters alongside other YARN-managed applications. In this mode, YARN handles resource allocation, scheduling, and monitoring of Spark application containers.
Apache Mesos Mode:
Apache Mesos is a general-purpose cluster manager that can run various distributed applications. Spark can be run on a Mesos cluster, sharing resources with other Mesos-managed applications. This mode allows better resource sharing and utilization, as Mesos dynamically allocates resources based on application requirements.
Kubernetes Mode:
Apache Spark can also be deployed on Kubernetes, a container orchestration platform. Kubernetes provides features for automatic scaling, resource isolation, and fault tolerance. Spark on Kubernetes allows you to run Spark jobs as native Kubernetes applications, simplifying cluster management and resource allocation.
Local Mode:
In Local mode, Spark runs on a single machine without any distributed setup. It is primarily used for development, testing, and debugging purposes, as it allows developers to quickly iterate on Spark applications without the overhead of setting up a full cluster.
Each of these architecture types comes with its pros and cons, and the choice depends on factors like the size of the data, the complexity of the processing tasks, existing infrastructure, and the level of isolation required. Organizations may opt for a specific architecture type based on their use case and available resources.
Moreover, Spark’s flexible architecture enables it to integrate with various storage systems (e.g., HDFS, Amazon S3), messaging systems (e.g., Apache Kafka), and databases (e.g., Apache Hive, Apache HBase). This integration further enhances Spark’s capabilities and makes it a versatile solution for big data processing.
Apache Spark Components:
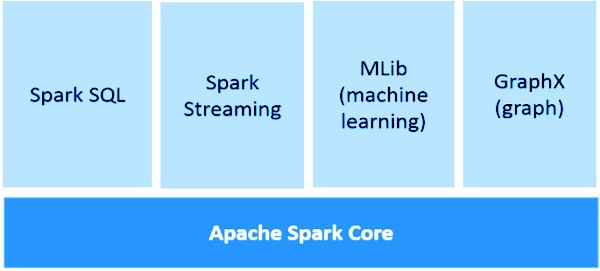
Apache Spark Core:
Spark Core is the underlying general execution engine for spark platform that all other functionality is built upon. It provides In-Memory computing and referencing datasets in external storage systems. It consists of 5 components.
- Driver Program: The driver program is the main entry point of a Spark application. It runs on the master node and defines the application’s high-level control flow, orchestrating the execution of tasks on worker nodes. The driver program also maintains the SparkContext, which serves as the connection to the Spark cluster.
- SparkContext (SC): The SparkContext is the core component that represents the connection to a Spark cluster. It is responsible for coordinating the execution of tasks across the cluster and managing the distributed data sets. The SparkContext serves as the entry point to interact with Spark APIs and RDDs (Resilient Distributed Datasets).
- Resilient Distributed Datasets (RDDs): RDDs are the fundamental data abstractions in Spark. They are immutable, fault-tolerant collections of objects that can be processed in parallel across the nodes in a cluster. RDDs can be created from external data sources or by transforming existing RDDs through operations like map, filter, reduce, and more.
- Transformations: Transformations in Spark are operations applied to RDDs to create new RDDs. Examples of transformations include map, filter, flatMap, groupByKey, reduceByKey, and many others. Transformations are executed lazily, meaning they don’t compute the results immediately, but rather build a logical execution plan (DAG) that is optimized and executed when an action is called.
- Actions: Actions are operations that trigger the execution of transformations and return results to the driver program or write data to external storage. Examples of actions include count, collect, save, reduce, take, and more. When an action is called, Spark computes the DAG generated by the transformations and executes the entire pipeline.
Spark SQL:
Spark SQL provides a module for working with structured and semi-structured data using SQL or HiveQL syntax. It enables users to execute SQL queries on DataFrames, which are distributed collections of data organized into named columns. Spark SQL seamlessly integrates with Spark’s other components, allowing users to combine SQL queries with RDD-based processing.
Spark Streaming:
Spark Streaming is a component that enables real-time stream processing and analytics. It ingests data in mini-batches and processes them using the same RDD-based API used in batch processing. Spark Streaming allows organizations to analyze and gain insights from real-time data streams, such as log files, social media updates, and sensor data.
ML lib:
MLlib is Spark’s scalable machine learning library, offering various algorithms and tools for building and deploying machine learning models at scale. It provides support for classification, regression, clustering, collaborative filtering, and more.
GraphX:
GraphX is a distributed graph processing library in Spark, designed for graph-parallel computation. It enables users to manipulate and analyze graphs, making it suitable for social network analysis, PageRank, and other graph-related tasks.
These components work together cohesively, allowing developers and data scientists to harness the power of distributed computing and process large-scale data efficiently with Apache Spark.
Use Cases of Apache Spark:
- Big Data Processing: Spark is the go-to solution for processing and analyzing massive datasets, allowing businesses to gain valuable insights from their data quickly.
- Machine Learning: With MLlib, Spark is used to build and deploy machine learning models for various applications, such as recommendation systems, fraud detection, and sentiment analysis.
- Real-time Analytics: Spark Streaming enables real-time analytics, making it ideal for monitoring social media trends, analyzing log data, and processing IoT sensor streams.
- Graph Processing: Spark’s GraphX library provides graph processing capabilities, which are valuable for social network analysis, connectivity analysis, and other graph-related tasks.
Conclusion:
Apache Spark has revolutionized the way big data is processed and analyzed. With its speed, scalability, and versatility, Spark has become a powerful tool for organizations to gain valuable insights from their data. Whether you are dealing with batch processing, real-time analytics, or machine learning, Spark’s unified platform and ease of use make it an excellent choice for a wide range of big data processing tasks. Embrace the power of Apache Spark, and unlock the potential of your data to drive business success in the digital age.

