

Ready to revolutionize data workflows? Explore the enchanting world of Apache Airflow demystified and discover the key to supercharging your data processes with live project.
Table of Contents
- Introduction:
- Understanding Apache Airflow:
- Supercharging Data Processes with Apache Airflow:
- Weather Report Data Pipeline
- Real-world Applications and Success Stories:
- Conclusion:
Introduction:
In the ever-evolving landscape of data management, Apache Airflow emerges as a transformative force, reshaping the way organizations approach data processes. Understanding its nuances is crucial in navigating this new era of efficiency and automation. Airflow plays significant role in Data Engineering
Overview of Apache Airflow:
Apache Airflow, an open-source platform, orchestrates complex workflows through Directed Acyclic Graphs (DAGs). These visual representations allow for the structured execution of tasks, offering a comprehensive approach to data management.
Importance of Data Processes in Today’s Landscape:
As businesses grapple with massive volumes of data, the significance of streamlined data processes cannot be overstated. Apache Airflow becomes the linchpin, offering a systematic framework to handle data workflows efficiently, ensuring data-driven decisions with precision.
Understanding Apache Airflow:
Definition and Core Concepts:
At its core, Apache Airflow revolves around DAGs – Directed Acyclic Graphs. These represent the flow and dependencies between tasks, establishing a clear sequence for execution. Within this framework, operators and tasks play pivotal roles in defining the actions to be taken at each step.
DAGs (Directed Acyclic Graphs):
DAGs provide a structured approach to visualize and comprehend the intricacies of data workflows. They offer a bird’s-eye view of dependencies, ensuring tasks are executed in a logical order without circular paths.
Operators and Tasks:
In the realm of Apache Airflow, operators represent units of work, encapsulating the essence of individual tasks. From simple BashOperators for shell commands to PythonOperators for executing Python functions, and SensorOperators for monitoring external conditions, a diverse set of operators empowers users to tailor tasks to their specific needs.
Scheduler and Executors:
The scheduler acts as the conductor, orchestrating the execution of tasks as defined in the DAGs. Executors, on the other hand, dictate the mechanism by which these tasks are carried out. This meticulous orchestration forms the backbone of Airflow’s operational prowess.
Setting Up Your Airflow Environment:
Installation and Configuration:
Embarking on the Airflow journey begins with a seamless installation process, followed by meticulous configuration to align the platform with specific organizational requirements. This step-by-step setup ensures a robust foundation for workflow execution.
Apache Airflow installation in Python:
pip install apache-airflow
Starting the Server:
airflow standaloneExploring the Web UI:
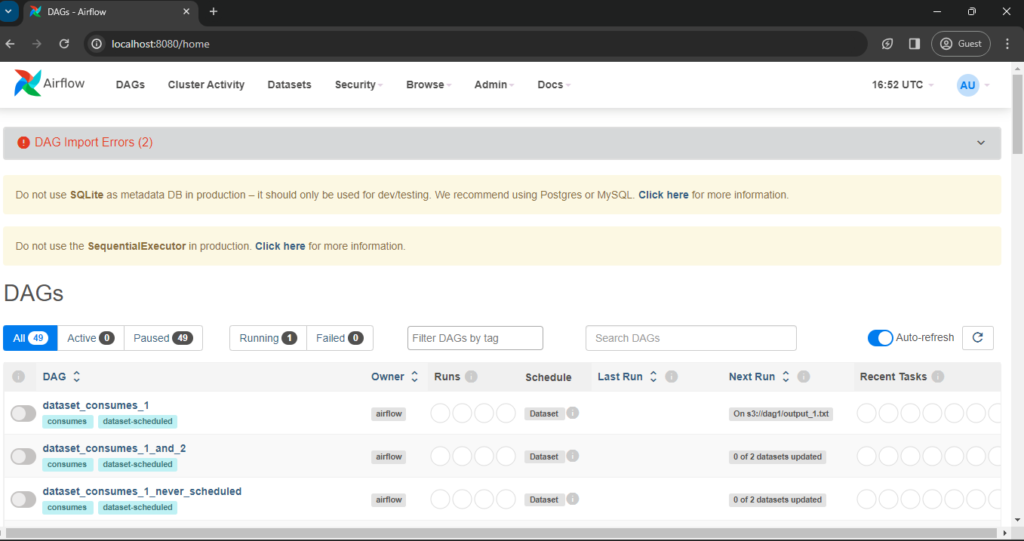
The Web UI serves as the control center, providing an intuitive interface for users to monitor, manage, and visualize DAGs and task executions. Navigating this user-friendly environment enhances the overall Airflow experience.
Access the apache airflow UI through following url –> http://localhost:8080/
Supercharging Data Processes with Apache Airflow:
Creating Dynamic Workflows:
The dynamism of Apache Airflow shines through in the creation of workflows with parameters and templates. These dynamic elements inject flexibility into processes, allowing for adaptability in diverse data scenarios.
Parameters and Templates:
Parameters and templates facilitate the customization of workflows, enabling users to input variables and configure tasks dynamically. This adaptability proves invaluable in handling varying data sources and processing requirements.
Conditional Dependencies:
Apache Airflow’s prowess extends to the establishment of conditional dependencies, allowing tasks to be executed based on predefined conditions. This conditional logic ensures a responsive and intelligent workflow execution.
Leveraging Operators for Various Data Tasks:
BashOperator, PythonOperator, and SensorOperator serve as the workhorses of Apache Airflow, each tailored for specific data tasks.
BashOperator for Shell Commands:
Executing shell commands seamlessly integrates external scripts and commands into workflows, expanding the scope of data processing capabilities.
PythonOperator for Python Functions:
PythonOperators facilitate the integration of custom Python functions, opening avenues for data transformation, analysis, and manipulation within the workflow.
SensorOperator for Sensor Tasks:
SensorOperators add a layer of intelligence by monitoring external conditions or file availability, ensuring workflows respond dynamically to real-time changes.
Managing Dependencies Effectively:
Upstream and Downstream Dependencies:
Efficient task execution relies on the establishment of clear dependencies. Upstream dependencies dictate tasks that must be completed before the current task, while downstream dependencies outline tasks reliant on the current one.
Trigger Rules for Task Control:
Airflow’s trigger rules allow users to define the logic governing task execution. Whether all_success, all_failed, or one_success, these rules empower users to exert fine-grained control over workflow behavior.
Scaling and Parallel Execution:
Parallelizing Tasks with Celery:
Scaling up data processing capabilities is achieved through the integration of Celery, a distributed task queue system. This parallel execution enhances performance, particularly in scenarios demanding high computational intensity.
Best Practices for Performance Optimization:
Optimizing performance involves adherence to best practices, encompassing DAG structure, operator choice, and strategic configuration. These considerations collectively contribute to a finely tuned Airflow environment.
Weather Report Data Pipeline
This project is built on apache airflow to get the weather report
weather_etl.py
import requests
import pandas as pd
import json
from datetime import datetime
def run_weather_etl():
API_key = ''
countries = ['India','London','Jamaica', 'Haiti', 'Montserrat', 'Barbados', 'Cuba', 'Dominican Republic', 'Saint Lucia', 'Antigua and Barbuda', 'Belize', 'Aruba']
caribbean_countries = []
maxtemp = []
mintemp = []
humidity = []
weather = []
windspeed = []
for country_names in countries:
url = f'http://api.openweathermap.org/data/2.5/weather?q={country_names}&APPID={API_key}&units=imperial'
response = requests.get(url)
data = response.json()
formatted_json = json.dumps(data, sort_keys = True, indent = 4)
caribbean_countries.append(data['name'])
maxtemp.append(data['main']['temp_max'])
mintemp.append(data['main']['temp_min'])
humidity.append(data['main']['humidity'])
weather.append(data['weather'][0]['description'])
windspeed.append(data['wind']['speed'])
countries_weather_df = pd.DataFrame()
countries_weather_df['Names'] = caribbean_countries
countries_weather_df['Max_Temp'] = maxtemp
countries_weather_df['Min_Temp'] = mintemp
countries_weather_df['Humidity'] = humidity
countries_weather_df['Weather'] = weather
countries_weather_df['WindSpeed'] = windspeed
countries_weather_df.to_csv('weather.csv')
weather_dag.py
from datetime import timedelta
from airflow import DAG
# from airflow.operators.python_operator import PythonOperator
from airflow.operators.python import PythonOperator
from airflow.utils.dates import days_ago
from datetime import datetime
from weather_etl import run_weather_etl
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2020, 11, 8),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=1)
}
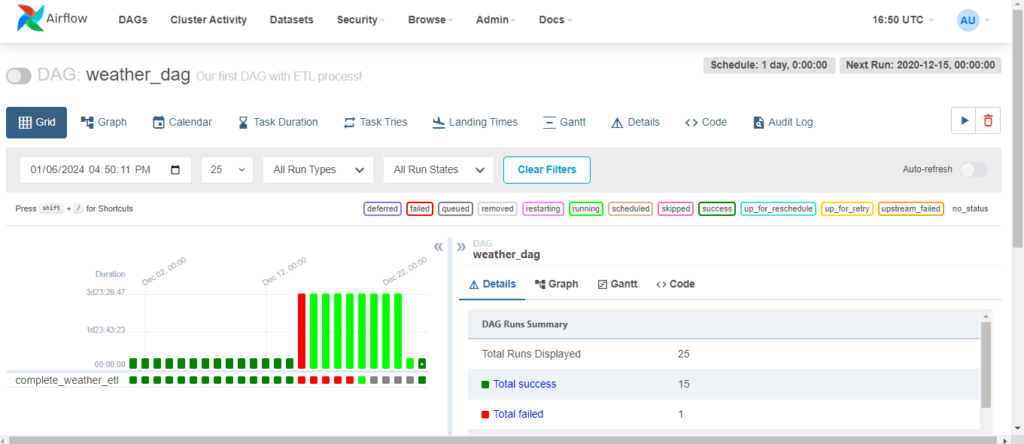
dag = DAG(
'weather_dag',
default_args=default_args,
description='Our first DAG with ETL process!',
schedule=timedelta(days=1),
)
run_etl = PythonOperator(
task_id='complete_weather_etl',
python_callable=run_weather_etl,
dag=dag,
)
run_etl
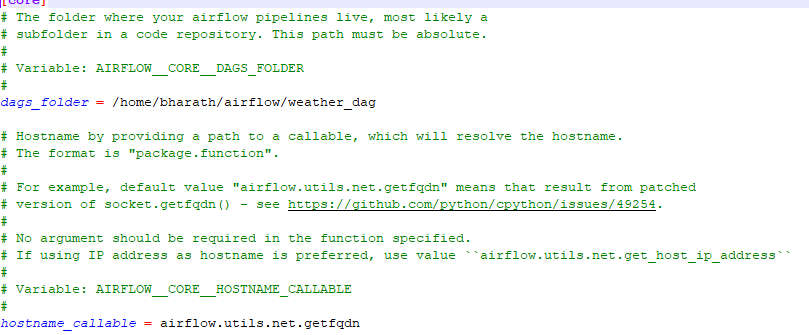
Update the dag folder with weather report script folder in airflow.config file:
Get the complete code in the github repository –> Weather report using airflow
Real-world Applications and Success Stories:
Case Studies of Companies Benefiting from Apache Airflow:
Examining real-world applications unveils the transformative impact of Apache Airflow on organizations. Case studies elucidate how Airflow facilitates the streamlining of ETL processes and the automation of data pipelines, resulting in heightened operational efficiency.
Streamlining ETL Processes:
Apache Airflow’s ETL prowess surfaces prominently in scenarios where data extraction, transformation, and loading require seamless orchestration. The platform’s versatility in managing these processes ensures a streamlined and error-resistant ETL pipeline.
Automating Data Pipelines:
Automation lies at the heart of Apache Airflow’s success stories. Witnessing the automation of data pipelines showcases how the platform minimizes manual intervention, accelerates processes, and contributes to the overall efficiency of data operations.
Conclusion:
Recap of Key Takeaways:
Summarizing the key takeaways underscores the transformative capabilities of Apache Airflow in revolutionizing data processes. From DAG orchestration to operator versatility, each aspect contributes to a holistic data management solution.
Encouragement for Readers to Dive into Apache Airflow:
Encouraging readers to embark on their Apache Airflow journey, the article emphasizes the platform’s user-friendly nature and its potential to reshape the way organizations approach data processes.
Closing Thoughts on Supercharging Data Processes:
In conclusion, the article leaves readers with a final reflection on the supercharging potential of Apache Airflow. As organizations navigate the complexities of modern data landscapes, Airflow stands as a beacon, offering a robust framework to elevate data processes into a realm of unparalleled efficiency and agility.

